在获得一些主流媒体的关注之后,ProgPoW 开发团队 IfDefElse 收到了许多算法方面的提问,他们对其中几个常见问题做出了解答。经原文作者的同意,矿视界对此进行了翻译报道。
1
问:在以太坊治理方面,你们的立场是什么?
答:暂无立场,我们觉得许多问题应该留给社区来回答,比如是否或者说何时采用 ProgPoW。我们负责提出新的算法,并乐意回答与之相关的技术性问题。
2
问:ProgPoW 从何而来?
答:IfDefElse 是分析和优化 PoW 算法的一个小团队。我们观察到 ETH 社区一再要求使用一种新的 PoW 算法,在这种算法中,专业的 ASIC 矿机和常规硬件设施比起来,优势不大。眼看着诸多算法在 ASIC 矿机面前不堪一击,实在令人心痛,每次新的 ASIC 矿机问世都会让整个 ETH 社区陷入沮丧。
于是在 2018 年春天里的一天,我们就有了通过修改 Ethash 算法,使其达到 GPU 挖矿预期效果的想法。初步编辑好该算法后,我们把它放到了 GitHub 公共版块上进行研发和微调。
3
问:谁对 ProgPoW 进行了测评?
答:在一次收集算法使用反馈的过程中,我们幸运地收到了来自以太坊基金会工程师,以太坊核心研发工程师,NVIDIA 工程师和 AMD 工程师的反馈邮件。NVIDIA 和 AMD 工程师都对该算法作出了总体正面的评价。
值得一提的是,有两处算法的更新优化是基于社区成员 mbevand 和 Schemykh 的评价作出的。
4
问:AMD 作何反应?
答:AMD 的回应解决了两大疑虑:
如果用 ProgPoW 算法替代 Ethash PoW 算法,难道 ASIC 矿机厂商就没办法迅速研究开源代码并制造专门 ASIC 矿机吗?
ProgPoW 算法会不会让 GPU 矿工挖以太难上加难?
AMD 一位工程师给出了肯定回答,理论上是可以针对ProgPoW 造新的 ASIC 矿机,但这需要制造方有专门的 GPU 知识背景,尤其是内存控制器技术。
不仅如此,他们还表达了对缓存(存在本地数据共享和 AMD 芯片上的数据)大小的担忧。
他们在邮件中提到,不论缓存是 8KB 还是 16KB,AMD 和 NVIDIA 在性能上无大差别。但在 32KB 和 64KB 时就可能会对两种 GPU 厂商架构产生重大影响,在 Polaris 和 Vega 上也会存在不兼容性。
根据他们的反馈,我们把 PROGPOW_CACHE_BYTES的大小设置为 16KB 。
5
问:NVIDIA 作何反应?
答:NVIDIA 工程师大体同意我们的方法。他们说,该算法用运算填补了内存访问间的漏洞,而不是让 GPU 像高贵的内存控制器一样无所事事地闲置在那。
他们主要的担忧是,如果算法里增加太多随机运算,最后会变成受计算限制,而非受存储限制。如此一来,为受计算限制算法打造的 ASIC 矿机可能会获得更大的效率和增益。
根据他们的反馈,我们微调了 PROGPOW_CNT_CACHE 和 PROGPOW_CNT_MATH 以保证该算法对当下大部分 GPU 仍保有受存储限制。
6
问:如果 ProgPoW 是在主回路上调用模并使用 kiss99() 写法来选择随机指令,那么针对这一算法设计的 ASIC 矿机难道不会更加高效吗?
答:这是第一次查看该算法时常会有的误区。事实上,在主回路上模和 kiss99() 写法的调用,是由 CPU 计算并以此生成一个随机程序,然后再由 CPU 进行编译的。GPU 负责的是执行优化代码,而这些代码已经解决了执行何种指令和使用何种混合状态的问题。
正如 Alexey 所言,ProgPoW 每 50 个区块生成一次源代码。生成程序示例请见:kernel.cu.
我们也将在标准中作进一步说明。
7
问:为了编译生成的源代码,矿工需要安装AMD 或者 NVIDIA软件开发工具包吗?
答:不需要。AMD 和 NVIDIA 的驱动中包含 OpenCL,DirectX 和 Vulkan 编译器。对于 CUDA 来说,二进制内核文件会和小部分软件开发工具包一起分配。
8
问:ProgPoW 算法有 GPU 架构上的偏好吗?
答:没有,ProgPoW 算法的设计初衷就是尽可能地保证公平性。OpenCL 和 CUDA 在执行上并无差异,16KB 大小的缓存在这两种架构上都能顺畅运行。
我们避免了只在一个架构上进行 16 位或 24 位运算,无论是 AMD 编入索引的寄存器文件,还是 NVIDIA 的 LOP3,所有的操作都得到了跨代体系架构的良好支持。
用 ProgPoW 算法的 GPU 在挖矿工作负载中的性能也将反映该 GPU 的平均游戏性能。
9
问:为什么经过大量修改 VBIOS 的 GPU,在 Ethash 和 ProgPoW 之间的速度差反而比预期慢 2 倍以上了?
答:ProgPoW 读取每哈希的内存是 Ethash 的两倍,因此预期哈希率为1/2。我们之前报告的所有调优和样本哈希率(详见“Results:Hashrate”)都是在以正常频率运行的 GPU 上面完成的。为降低核心频率而大量修改 VBIOS 将会导致矿机运行该算法时受计算限制,而非受存储限制。
如果用户需要更换到新算法,VBIOS 的修改与调优将需要重新进行。
10
问:你们能讲讲 Ethash ASIC 矿机如何比 GPU 矿机效率高出两倍吗?
Ethash 算法只需执行 3 个组件:
高带宽存储器(用于 DAG 访问)
Keccak f1600 引擎(用于初始/最终哈希)
微型计算核心(用于内回路 FNV 和模块调用)
FPGA 的数据表明,Keccak 计算所耗费的功率几乎可以忽略不计。我们估计,在执行 Ethash 算法时,大约只有 1/2 的 GPU 功率花在了内存访问上。而 Ethash ASIC 矿机的 Keccak 和计算核心的功率可以忽略不计,其功率主要消耗在内存访问上,所以 GPU 在挖矿效率上还有两倍的改进空间。
当前 Ethash 挖矿硬件快速摘要:
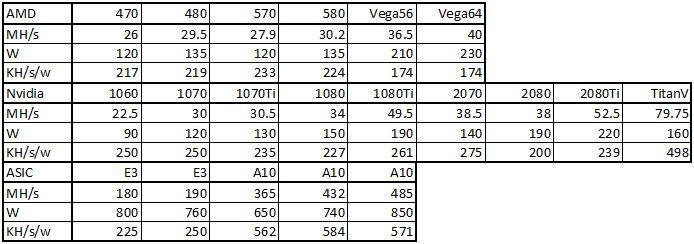
除 Titan V,所有数据均来自 whattomine.com 和 asicminervalue.com。
第一代 Ethash ASIC 矿机,比特大陆的 Antminer E3 和 GPU 矿机相比没有任何效率上的优势。这是因为它的 DDR3 内存比 GPU 矿机的 GDDR 内存功耗更高。
据我们所知,尚未发布的 Innosilicon A10 ETHMaster 据说在效率上会有更优表现。因为 Innosilicon 在该系列矿机上使用了 GDDR6 IP 技术,这将使得它的效率可以达到目前最高效挖矿 GPU RTX 2070 的两倍。
11
问:HBM 的实用性如何?
答:我们最初的算法评估是使用同种内存类型进行同标准比较的。HBM 功耗低,但价格贵,就显得不够实用。举个例子,带有 HBM 的 NVIDIA Titan V 比起 A10 ETHMaster,效率上仅逊色一点,但成本高达 3,000 美元,明显没有实用性。
带有 HBM 的 AMD Vega 卡价格倒是合理,但又因为一些原因它的算力只能达到 175 KH/s/W。Vega 效率受何限制我们尚不确定,增加访问大小能够明显改善这一情况(带宽利用率从 61% 提升至 75% —详见“Results:Hashrate”)但 Vega 显卡的功耗仍然过高。我们期待刚刚宣布的双倍带宽 AMD Radeon VII 显卡能在效率上有显著改善。
我们预估 HBM 的功率约为 GDDR6 的一半,如果使用 HBM 制造昂贵的 Ethash ASIC 矿机,算力将超 1 MH/s/W,这效率大约是市面上常规 GPU 的 4 倍。
12
问:ProgPoW ASIC 能有多高效率?
答:ProgPoW 旨在大幅减少专用 ASIC 矿机的效率增益。该算法执行需满足如下组件:
高带宽存储器(用于 DAG 访问)
Keccak f800 引擎(用于初始/最终哈希)
大型寄存器文件(用于混合状态)
高吞吐量 SIMD 整数学(用于随机运算)
高吞吐量 SIMD 缓存(用于随机缓存访问)
Keccak 容量变小,因此它在 GPU 上的功耗也已经可以忽略不计了。这么一来,ASIC 矿机在降低功耗方面的优势也将不复存在。
为了执行随机序列,ProgPoW ASIC 矿机需要执行和 GPU 上的计算核心非常相似东西。所有 SIMD 的寄存器访问、数学运算和缓存访问都需要类似 GPU 的运行环境。
没错,ProgPoW ASIC ISA 能够通过精确设计,使之匹配 ProgPoW 算法,例如删除浮点、增加显式 merge() 等操作。然而这种专业化只会提供少量的边缘效益,而不是数量级的收益增加。
乐观来说,我们假设精心设计的 ProPoW ASIC ISA 可以移除 1/4 计算核心功耗。由于 GPU 内核在执行 ProPoW 时要活跃得多,我们估计内存接口大约消耗 GPU 功率的 1/3。那么使用 GDDR 的 Prop PoW ASIC 矿机相对功耗则为:
1/3 (内存) * 1 + 2/3 (计算) * 3/4 = 5/6
优势为 1.2 倍
若使用 HBM,则 ProgPoW ASIC 矿机的相对功耗则为:
1/3 (内存) * 1/2 + 2/3 (计算) * 3/4 = 2/3
优势为 1.5 倍
13
问:能在 FPGA 上运行 ProgPoW 吗?
答:首先,在 FPGA 上运行 ProgPoW 存在实际问题。因为随机程序每 12.5 分钟更改一次,因此需要经常编译和加载新的比特流。完成此任务的工具和设施基本上不存在。
就算忽略这个问题,ProgPoW 也不能很好的映射到 FPGA,FPGA 对于计算密集的算法(如 Keccak 或 Lyra)行之有效。通过将多个操作封装到单个时钟周期中,同时运行多个操作,这些算法可以显著地提高性能和降低功耗。
ProgPoW 算法循环有许多在序列中交错的缓存读取,这极大地减少了可以打包到单个时钟周期或并行运行的操作。在 ProgPoW 算法下,FPGA 的打包操作既降低了挖矿硬件的性能,又增加了信息通道的长度。因为大型的混合状态(16 lanes * 32 regs * 4 bytes = 2 kilobytes),增加的信息通道长度也成了一个问题。
如果沿每个信息通道阶段性地复制此大混合状态,则会浪费大量电能。当然,我们也可以把混合状态存储在寄存器文件中,让 FPGA 的计算核心看起来很像 ASIC 或 GPU,但那样做的话, FPGA 的运算效率将显低于 ASIC。
14
问:以上所有问答貌似十分冗长,能简单做个总结吗?
答:当然
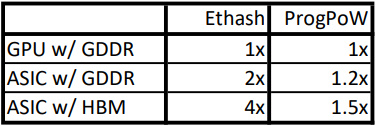
挖矿硬件的相对效率
我们最初对 Ethash 和 ProgPoW 的 2 倍和 1.2 倍估计是假设一样内存类型的同标准比较。在撰写本文时,我们已经意识到,当大多 GPU 使用 GDDR 时,我们也要进行不同标准的比较,比如拿使用 HBM 的 ASIC 矿机作比较。
原文链接:
https://medium.com/@ifdefelse/progpow-faq-6d2dce8b5c8b
原作者: IfDefElse 翻译&校对:有条鱼
本文由矿视界翻译整理编辑,如需转载,请标明出处。
声明:此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。本网站所提供的信息,只供参考之用。






