给 Filecoin 以矿机,而不是给矿机以 Filecoin。
原文标题:《Filecoin 硬件编年史之一》
撰文:lb
给岁月以文明,而不是给文明以岁月。
给 Filecoin 以矿机,而不是给矿机以 Filecoin。
标题为「编年史之一」,是因为这个变化并未终结,甚至主网上线之后,也可能持续发生变化。
史前时代:2017 年 —— 2019 年 2 月 13 日

这个时代,是大多数人分不清楚 IPFS 和 Filecoin 的区别的时代,是相信 Filecoin 挖矿就是组装存储服务器的时代,是认为硬件优势就是核心优势的时代。
这时所谓的 IPFS 服务器或者 Filecoin 矿机,尽管很多产品搭配着服务器外衣,但拥有的却是 PC 内脏。咋一看,外观是 2U/3U/4U 的机架式服务器,但里面的主板插的是台式机 CPU,以及不带 ECC 纠错功能的内存条。更有甚者,采用 J1900 这款赛扬 CPU 的低端机器曾经一度占据了这类机器数量的绝大部分,甚至成为某些骗局盘子的门面机型。这些机器,内存从 1GiB,2GiB 到 8GiB 的都有,鲜有超过 16GiB 的配置。
做这样的配置的原因很简单。存储嘛,关键点在于大量的硬盘能存更多的数据,不像比特币那样做很多无意义的 HASH 计算。这也是事实。实际上,大量的 NAS 设备,甚至企业级的 NAS 设备(高性能的分布式存储除外),对于 CPU 和内存真的没有太高的要求。
这个时代的每个厂商,都说自己掌握了核心技术,都说自己靠谱。大家更为关注的是「性价比」——谁的机器便宜,谁的单 TB 成本最低。
不过,很多厂商,连史前时代都没有成果,就已经跑路了。当然,也有更多的厂商,把机器直接转型,去挖其他币种了。不管什么样配置的机器,总有可以挖的——实在找不到项目,也可以创造出项目嘛。
这个阶段,协议实验室隔空警告大家:不要买所谓的 mining machine。
春秋时代:2019 年 2 月 14 日 —— 2019 年 11 月底

Filecoin 的代码总算公布了。虽然 Bug 很多,但作为一个伟大的项目,大家都可以理解,也猜到了它的上线过程,长期又曲折。事实上,和其他区块链项目相比,我们每天都可以看到它的代码和文档更新,可以从各个角度来「感受」它的算法,了解到它的活跃度。
但这时,许多人发现了一个吃惊的事实。不对劲啊!怎么花在计算上的时间比存储上的时间多呢?用一台普通的机器,1GiB 的数据,真正写入硬盘只需要几秒钟(如果是 RAID 可能更快),但做复制证明的 Seal 操作,要耗费数十分钟?这个不是一个存储项目吗?
这就带来了一个很严重的问题:以前配置很低的机器,比如 J1900,看来是不行的了。至少做 Seal 是不行的,要知道,Seal 可是整个 Filecoin 挖矿过程中的最耗费时间的步骤。当然,要利用旧机器也不是不行,就把它们当成一个个存储柜吧。稍微好一点点的配置,仍然可以发挥余热。但新加的机器,配置至少要更强劲点。干脆就多来点服务器 CPU 吧,内存又稍微大一点点吧。逐渐地,二手服务器进入这个市场,入门级的至强 E3,淘汰很久的至强 E5645 等 CPU,E5 2600 系列 v1 和 v2 CPU,都蜂拥而至。内存大小渐渐地以 16GiB 为主,开始有 32GiB 的出现。
许多人已经认为硬件配置过高了,都 32GiB 内存了,再高的话,那是要逼人造反了 !甚至一些人吵着说,这个还是不是存储项目了?怎么偏离方向了呢?但是,事物的发展方向,是不以人的意志为转移的。就像我们觉得股票已经跌得够低了,不能再跌了,所以舍不得卖,但第二天发现跌入了一个新的谷底。如果觉得这个硬件配置高,过半年再回过头来看,就会认为自己犯了经验主义错误。
不过,仍有人通过技术的敏感度,推测到后续的硬件要求越来越高,硬件配置好一点,在性价比方面并不会吃亏。比如,至少采用 E5 v3 系列的服务器 CPU,在支持 avx2 指令集等特性的情况下,拥有比 v2 更好的性能,也具有更高的性价比。
这个时代,大家逐渐觉察到,容量不是唯一,甚至容量就不是一个问题。算力(power)积累速度,才是关键。否则,拥有再多的硬盘,看到的只是跑得快的人在分钱。
官方的算力排行榜开始出现。各路厂商在营销方面的手段也升级了,从纯宣传自己技术强,慢慢演变到说自己可以上榜。于是出现了很多「第一名」。但因为代码本身的很多 Bug,这个排行没有形成气候,关注的人不算多。
而且,大家意识到一个问题。有了机器,把 Filecoin 跑起来,甚至就是简单的编译和运行,都不是一件容易的事情。如果要跑得更好,更稳定,竟然需要自己去修改代码。这些都需要大量的研发资源,以及技术沉淀。于是,人们意识到,软件、运维、持续不断地迭代,比硬件更重要。官方代码每天都在变,凭什么自己不努力呢?
这个阶段,协议实验室仍然对大家说:最好不要买所谓的 mining machine。
春秋到战国的过渡:2019 年 11 月底 —— 2019 年 12 月 12 日测试网上线前
协议实验室突然宣布,挖矿要 GPU。这个事情掀起了轩然大波。其实 GPU 对于复制证明和时空证明的加速,一直都有人在研究,在拥有 GPU 的情况下,像 FFT 快速傅里叶变化和 Multiexp 椭圆曲线等算法,的确会快很多。但为了网络更安全,协议实验室引入了两个重大的变更,对硬件的配置需求也急剧增加,GPU 从选配几乎变成了标配:
在出块的时候,采用了选举证明(Election PoSt)。为了在一个区块高度内完成(最好是半个区块内就要完成),协议实验室建议使用 GPU。也就是说,如果不用 GPU,即使有算力,也很难有 FIL!那不是白挖了吗?
因为小容量扇区不安全,所以主网上线的时候,仅支持 32GiB 的扇区。虽然目前测试网支持 1GiB 扇区,但硬件标准至少要向 32GiB 扇区看齐了。
这样,新的硬件标准又滚烫出炉了。至少 128GiB 内存,最好是多核心的 CPU (相对高端的 Intel E5 v3 及以上系列,或者性能强劲的 AMD 线程撕裂者系列),有一块 NVIDIA 的 2080 Ti 显卡……CPU 和显卡,虽然稍微低配一点点也能跑,但效率就会打折扣了。内存少了,哼哼,那就对不起了,很容易 out of memory。
战国时代:2019 年 12 月 12 日测试网上线 —— 现在

测试网上线之后,Filecoin 的行业格局有了一些变化。至少所有的人都会盯着官方的算力排行榜以及出块效率、FIL 产出等参数了。其实,这些仅仅都是数字,并不能代表什么。但是,要获得这些数字,的确需要很多投入。研发的投入,以及设备的投入。
虽然 Filecoin 的市场可能很大,众多厂商能够一起瓜分这块蛋糕,但厂商之间的竞争,也在这个时代愈演愈烈。有各种榜首之争,各种吹捧和诋毁的文章,以及新的造神之作。有说刷榜是没意义的,有说上不榜至少可以说明没有技术;有说你的成本高,有说我的技术牛……这些都很正常,一个前辈说过,市场宣传需要嘛。主网上线了,自然见分晓,这里就不多说了。
测试网引领的一个重大变革是——集群挖矿模式成为主流。单机挖矿和集群挖矿,谁更好,大家众说纷纭。多个机器用不同的账号,看上去抗惩罚能力更强,且挖到的总 FIL 不一定少;集群的话,需要很多额外的开销用于内部协调,且内网数据传输也可能导致瓶颈,但是算力累积快,至少可以很快达到官方设置的出块算力阈值。但有一个非常重要的原因,让大家都不得不用集群:更大的总算力,更容易上榜,且在算力、出块率、获得 FIL 数目等方面,取得排名靠前的优势。
集群挖矿的话,每个厂家的实现都有不同。但至少在很大程度降低了对 GPU 的依赖性,出块的机器,做时空证明,需要 GPU,其他机器,可配可不配嘛。成本已经增加了这么多,再加一个不断涨价的 2080Ti,已经让人疯狂了。大家也意识到,Filecoin 硬件设备的非存储因素占据的成本比重越来越高。
当然,还有一些厂家继续提升单台设备的算力增长率,采用了更为高端的硬件设备。比如多张 GPU 同时使用,采用更好的 CPU 和更大的内存。算力变多了,成本也变高了,是否更有性价比呢?针对特定版本的程序来说,的确是的,前提是要有大量的代码级别优化,充分利用 GPU 的并行性。如果觉得这个还不够?那就上 FPGA,可以针对特定的运算实现优化;FPGA 做好了,甚至还可以做 ASIC 芯片。感觉有点复盘 BTC 矿机的成长之路了。这些东西,的确是有点技术含量,也不是那么容易做出来的。但是需要付出的不仅仅是硬件成本,还有更多的研发成本。不对,等等,是不是路走偏了,Filecoin 不是一个存储项目吗?怎么硬件配置和做深度学习的计算集群差不多了?
协议实验室仍然在耐心地告诫大家:在主网硬件配置标准没有公布之前,大家慎重。
隔离时代:2020 年新冠疫情发生之后
在大家都在讨论是否是新冠病毒导致 Filecoin 测试网第二阶段和主网推迟的事情时,协议实验室的团队正夜以继日地频繁更新代码。悄悄地,又发生了很多变化。
其中一个较大的变化是,复制证明的 precommit 阶段,winSDR 算法改成了 SDR。之前的 winSDR 是把数据按 128MiB 分成了一个个 window,这样可以通过并行计算的方法来加快计算速度。不过,这个算法是不安全的。比如,利用 GPU 等设备,可以做到更大程度的并行性,三下五除二,就把它搞定。这样就给链的安全带来隐忧。改成 SDR 之后,可以消除过度优化带来的负面作用,相关的计算只能串行操作,虽然时间更长了,但安全隐患大大降低。
安全性的提高是用更多的计算成本这个代价来换取的。单个任务只能用 1 个 CPU Core 的话,那还得了?不是大量的资源都被闲置了吗?虽然电表上的用电量下降了,但做完一个 Seal,需要很长很长很长的时间。矿工的心在滴血啊!那就同时跑多个任务吧?但 32GiB 扇区的计算是机器耗费内存的,并发任务多,需要的内存量就加大,连做基因计算的胖节点的内存都没有这么大!姑且不讨论主板有没有那么多内存条,疫情开始之后,内存价格的急剧上涨,已经让人揪心不已!
能不能少用点内存,支持更多的任务呢?自然他们也是想到了,于是有了 如下尝试。
但这个代码一直没有被合并,估计是太忙了,没有时间去解决这个过程中的很多具体问题。想法容易,做起来的细节还是非常多。但无论怎么样,硬盘的速度都比内存慢很多。即使是 NVMe SSD 也如此。何况前面加 CPU,加内存,加 GPU,已经要人抓狂不已,现在又加 NVMe?
为了让大家更安心接受 SDR,协议实验室的人只能拼命工作。野百合也有春天,漫长的 Seal 也可以加快那么一点点。于是,想到了看怎么榨干 CPU 的性能。在 SDR 过程中,计算每个 node,用的是 SHA256 哈希计算(就是比特币的那种哈希算法)。能否想到妙招,不依赖于新的硬件,就能给它加加速?嗯,有了,就用 SHA 扩展,通过新增的指令,极大提速了 SHA256 的计算。爽哉!等等,有点不对劲,这个 SHA 扩展好像是 Intel 提出的,但 Intel 的桌面 CPU 和服务器 CPU 都不支持,倒是 AMD 的 CPU 支持得很好。不过,这个也不是问题,因为协议实验室开发人员用的工作机器,就是 AMD 的线程撕裂者。自己的机器,自然要最先优化啦。虽然 CPU 价格超贵,但用起来超爽。
AMD 的 CPU 在服务器市场占有率一直不高,大量的服务器 CPU 仍然是 Intel 的。兼顾了自家用的 AMD,也照顾一下 Intel 吧。于是,就在 SIMD 指令集上面下工夫,看怎么利用这些指令集进行优化:
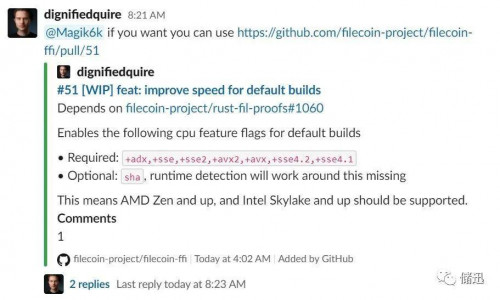
上面的 sse、sse2、sse4.1、sse4.2、avx、avx2 等都是常用的 SIMD 指令。SIMD 是单指令多数据的意思,就是一条指令可以进行多组计算,自然会快些。编译的时候经过相关优化,可以表现出比较好的性能提升。不过,有些较老的 CPU 就吃亏了,比如,E5 v2,不支持 avx2,那默认编译出来的版本,就不能运行。
但 sha 这个选项,让 AMD 的 CPU 效率提升更为明显。我甚至都怀疑是否 AMD 派人嵌入协议实验室内部,通过这种合情合理的方式,来提供自己的 CPU 在存储市场的占有率?嗯嗯,理论上有这个可能性。不过,那 NVIDIA 也有嫌疑。还有,测试网第二阶段都没有上线呢,算法随时可能再变更,Intel 还是有大把大把机会的……
道高一尺,魔高一丈。是否还是有想一些黑科技,能够突破这些瓶颈呢?也许有。不过,不要紧,算法是死的,人是活的,可以再变算法。那主网上线了呢?更新的步伐也是不会停止的,可以随时分叉嘛。这……难道不会有很多不满的情绪吗?比如,诸如成本、性能、能耗之类的指责。
这些问题显然都是有的。协议实验室也很明白。他们也想优化,也想适应更多的硬件。比如,下面这个讨论,盖了 66 层楼,就是针对许多硬件不支持默认编译配置导致无法运行的争论:

但无论如何,链的安全性是最重要的。前进的道路本身就是争议之路。但如果链不安全,比如,一个矿工占据了绝大多数算力,那这个链就完蛋了,所有人的一切努力都归零。
因此,再多的抱怨,都只能为安全让路。还是那句话:
给 Filecoin 以矿机,而不是给矿机以 Filecoin。
题外话
同样的价格,节点越多,性价比越高?
非也,如果 CPU、GPU、内存等存在较大差异,同一个节点,其算力累积的速度可能差几十倍。
同样配置的硬件,为什么价格不一样?
因为软件优化是决定 FIL 产出的核心因素。同样的硬件,运行的代码不一样,对硬件的优化可能存在天壤之别,在稳定性方面也各有差异。
现在内存价格已经涨了很多,那主网硬件标准定了,相关硬件价格是否会大涨?
风险和收益是密切相关的。提前确定硬件,虽然有可能会更便宜,但是存在着针对新版代码的算法无法做到最优化的风险(尤其是最近的频繁改动)。每个人对风险的预估不一样,这个只能大家自己决定,见仁见智了。
我的设备的配置低,是否也能参与到 Filecoin 挖矿?
看怎么定义挖矿了。如果把证明部分外包,很多时候也可行,就是看性价比的问题了。
未来硬件配置会持续变高吗?
也许。但也有可能链被认为足够安全了,准入门槛开始降低。但那是未来的事情。
来源链接:mp.weixin.qq.com
声明:此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。本网站所提供的信息,只供参考之用。






