PoREP算法,从window SDR改成SDR,时间并不长。新的PoREP算法NSE已经在酝酿中。NSE算法的全称:Narrow Stacked Expander PoRep。在rust-fil-proofs的feat/nse分支,可以查看NSE算法的实现。
文章使用的源代码的最后一个提交信息如下:
commit af4bdcb6da4b371230eed441218c459e99d32068 (HEAD -> feat/nse, origin/feat/nse)
Merge: 7e7eab2 578d12c
Author: porcuquine <1746729+porcuquine@users.noreply.github.com>
Date: Wed May 20 12:11:43 2020 -0700
Merge pull request #1118 from filecoin-project/feat/nse-update-neptune-alt
Feat/nse update neptune alt
理解NSE算法,可以从storage-proofs/porep/src/nse/vanilla/porep.rs中NarrowStackedExpander结构的replicate函数看起。
NSE,之所以称为NSE,因为N,Narrow。Narrow的意思是比之前的SDR算法,窄,每次处理的数据为一个Window。
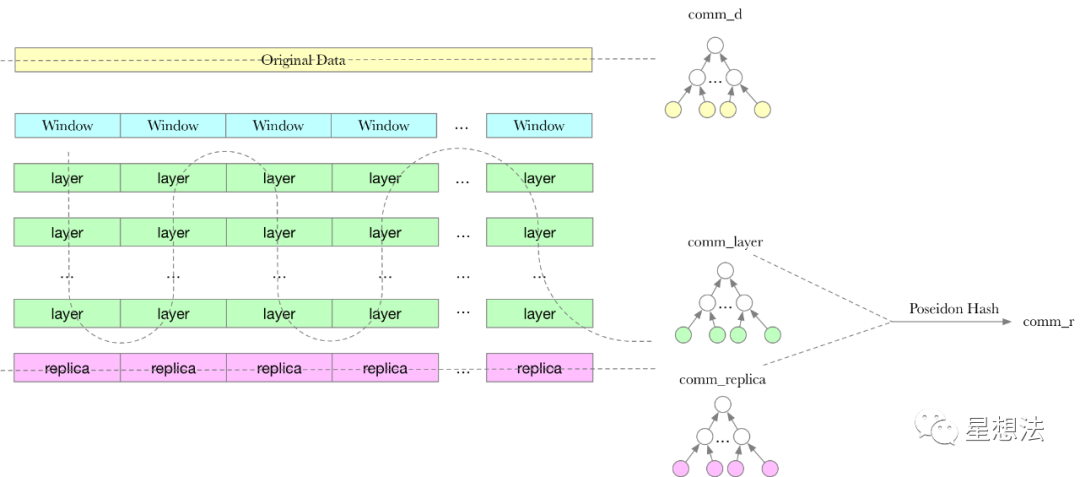
每个Window经过层层的处理,都会生成对应的Replica。所有Window对应的每一层的数据一起构建成Merkle树。所有Window对应的Replica的数据也一起构建成Merkle树。这两棵树树根的Poseidon Hash的结果作为comm_r。comm_d以及comm_r是需要上链的数据。
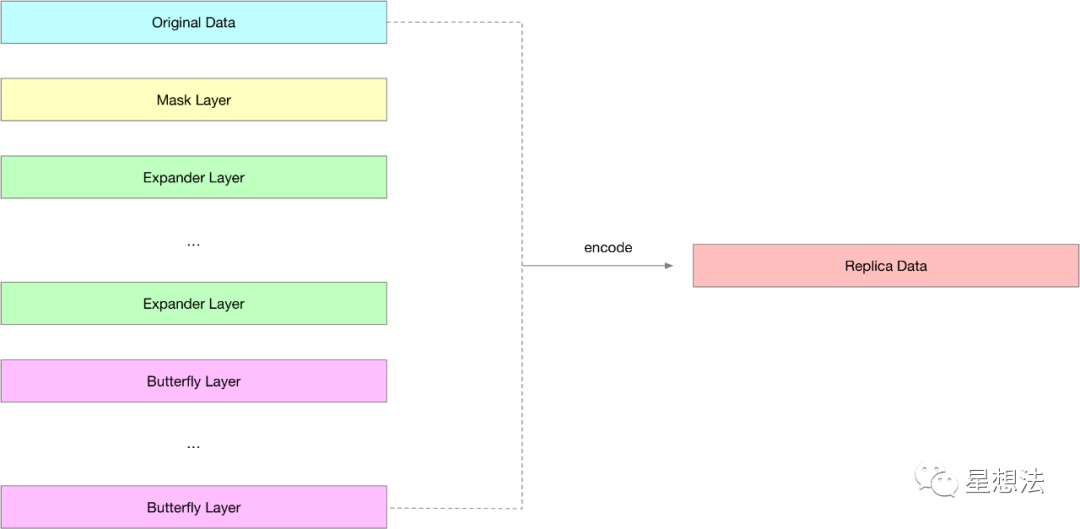
每个window需要经过很多层的处理,这些层分为mask layer,expander layer, butterfly layer。核心逻辑在storage-proofs/porep/src/nse/vanilla/labels.rs的encode_with_trees函数中。
层数的配置,以及Expander/Butterfly的一些参数配置都没有确定。从测试代码的配置看:
let num_windows = 1;
let rng = &mut XorShiftRng::from_seed(crate::TEST_SEED);
let replica_id = <PoseidonHasher as Hasher>::Domain::random(rng);
let config = Config {
k: 8,
num_nodes_window: (sector_size / num_windows) / NODE_SIZE,
degree_expander: 384,
degree_butterfly: 16,
num_expander_layers: 8,
num_butterfly_layers: 7,
sector_size,
};
window设置为1,expander的依赖设置为384,butterfly的依赖为16。总共15层。
Mask Layer
Mask Layer和具体的数据没有关系,和window编号/节点编号有关:
Expander Layer
Expander Layer基于ExpanderGraph生成依赖的上一层的节点的数据。这些数据和一些编号信息的sha256的结果作为新的节点的数据。示意如下:
parent节点的计算请查看storage-proofs/porep/src/nse/vanilla/expander_graph.rs中ExpanderGraphParentsIter结构的update_hash和next函数:
pub struct ExpanderGraph {
/// The number of bits required to identify a single parent.
pub bits: u32,
/// Batching hashing factor.
pub k: u32,
/// The degree of the graph.
pub degree: usize,
}
// node index - 4 bytes
self.hash[..4].copy_from_slice(&self.node.to_be_bytes());
// counter - 4 bytes
self.hash[4..8].copy_from_slice(&self.counter.to_be_bytes());
// padding 0 - 24 bytes
for i in 8..32 {
self.hash[i] = 0;
}
let mut hasher = Sha256::new();
hasher.input(&[&self.hash[..], &[0u8; 32]]);
self.hash = hasher.finish();简单的说,每个node依赖的parent的个数是degree*k个。parents的确定通过节点编号以及parents序号的hash结果来确定。
具体的hash计算逻辑,请查看storage-proofs/porep/src/nse/vanilla/batch_hasher.rs的batch_hash函数。
for (i, j) in (0..degree).tuples() {
let k = k as u32;
let (el1, el2) = (0..k).fold(
(FrRepr::from(0), FrRepr::from(0)),
|(mut el1, mut el2), l| {
let y1 = i + (l as usize * degree as usize);
let parent1 = parents[y1 as usize];
let current1 = read_at(data, parent1 as usize);
let y2 = j + (l as usize * degree as usize);
let parent2 = parents[y2 as usize];
let current2 = read_at(data, parent2 as usize);
add_assign(&mut el1, ¤t1, &modulus);
add_assign(&mut el2, ¤t2, &modulus);
(el1, el2)
},
);
// hash two 32 byte chunks at once
hasher.input(&[&fr_repr_as_bytes(&el1), &fr_repr_as_bytes(&el2)]);
}batch hash的名称,来自于batch,在做hash之前,需要将k个parents先做模加,模加的结果再做hash。
Butterfly Layer
Butterfly Layer的计算类似于Expander Layer,不同的是获取Parents的方式以及Parents的hash计算方式。Parents的计算依赖ButterflyGraph的实现:
pub struct ButterflyGraph {
/// The degree of the graph.
pub degree: usize,
/// The number of nodes in a window. Must be a power of 2.
pub num_nodes_window: u32,
/// Total number of layers.
pub num_layers: u32,
/// Number of butterfly layers.
pub num_butterfly_layers: u32,
}
fn next(&mut self) -> Option<Self::Item> {
if self.pos >= self.graph.degree as u32 {
return None;
}
let parent_raw = self.node + self.pos * self.factor;
// mod N
let parent = parent_raw & (self.graph.num_nodes_window - 1);
self.pos += 1;
Some(parent)
}Butterfly Layer的一个节点,依赖degree个前一层的节点。每个Parent序号的计算公式:
node + pos * factor
其中,node是节点编号,pos是Parents编号,factor是系数(和层的编号有关)。这种有固定间隔的依赖形状,有点像蝴蝶翅膀的条纹,所以称butterfly layer。
所有Parents的Hash计算,相对简单,就是所有Parent数据拼接后的Hash值。
// Compute hash of the parents.
for (parent_a, parent_b) in graph.parents(node_index, layer_index).tuples() {
let parent_a = parent_a as usize;
let parent_b = parent_b as usize;
let parent_a_value = &layer_in[parent_a * NODE_SIZE..(parent_a + 1) * NODE_SIZE];
let parent_b_value = &layer_in[parent_b * NODE_SIZE..(parent_b + 1) * NODE_SIZE];
hasher.input(&[parent_a_value, parent_b_value]);
}
let hash = hasher.finish();
在多层处理结束后,最后一层的bufferfly layer和原始数据进行encode,生成最后的Replica layer。计算过程,就是在最后一层bufferfly layer的基础上,再做一次bufferfly计算,结果和原始数据进行大数加法计算。详细的计算过程,请查看storage-proofs/porep/src/nse/vanilla/labels.rs的butterfly_encode_decode_layer函数。
总结:
PoREP的NSE算法,是SDR算法的另外一种尝试。尝试降低单个处理的数据大小(window),尝试不采用节点的前后依赖(layer的计算可以并行),加大单层的依赖,加大layer的层数。整个算法底层还是采用sha256算法。NSE算法可以理解为安全性和性能之间平衡的一种尝试。
声明:此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。本网站所提供的信息,只供参考之用。







